인덱스를 사용하는 이유와 그에 따른 트레이드 오프
인덱스
인덱스는 여러 가지 방식에서 사용될 수 있다. 예를 들어, 락 관점에서 보면 인덱스가 걸려있지 않은 테이블로 WHERE 조건 검색을 하면 전체 레코드가 락이 걸리는 반면 인덱스를 통해 WHERE 조건 검색을 하면 해당 레코드만 락을 걸어 락을 최소화할 수 있다. 또한 테이블 전체 파일을 읽기 보다는 상대적으로 작은 인덱스 파일을 읽어 더 빠르게 조회를 할 수 있다. 이러한 여러 가지 장점이 있는 인덱스에 대해 알아보고, 인덱스를 사용하는 대신 그에 따른 트레이드 오프가 무엇이 있을지 살펴보자.
인덱스의 데이터 저장방식(알고리즘)
데이터 저장방식(알고리즘)별로 구분할 경우 상당히 많은 분류가 가능하지만 대표적으로 B-Tree 인덱스와 Hash 인덱스로 구분할 수 있다.
- B-Tree 알고리즘은 가장 일반적으로 사용되는 인덱스 알고리즘으로서, 컬럼의 값을 변형하지 않고 원래의 값을 이용해 인덱싱하는 알고리즘이다. MySQL 서버에서는 위치 기반 검색을 지원하기 위한 R-Tree 인덱스 알고리즘도 있지만, 결국 R-Tree 인덱스는 B-Tree의 응용 알고리즘으로 볼 수 있다.
- Hash 인덱스 알고리즘은 컬럼의 값을 해시값으로 계산해서 인덱싱하는 알고리즘으로, 매우 빠른 검색을 지원한다. 하지만 값을 변형해서 인덱싱하므로 전방(Prefix) 일치와 같이 값의 일부만 검색하거나 범위를 검색할 때는 해시 인덱스를 사용할 수 없다. Hash 인덱스는 주로 메모리 기반의 데이터베이스에서 많이 사용한다.
위 내용을 봤을 때 B-Tree(Balanced Tree)는 컬럼의 원래값을 변형시키지 않고 인덱스 구조체 내에서 항상 정렬된 상태로 유지한다. 전문 검색과 같은 특수한 요건이 아닌 경우, 대부분 인덱스는 거의 B-Tree를 사용할 정도로 일반적인 용도에 적합한 알고리즘이다. 이러한 B-Tree 자료구조에 대해서 자세히 살펴보자
B-Tree

BST(Binary Search Tree)의 경우에는 각 노드에서 자식 노드를 최대 2개까지만 가질 수 있었지만 B-Tree에서는 자녀 노드의 최대 개수를 늘리기 위해 부모 노드에 key를 하나 이상 저장하도록 만든다. 이 때, key를 오름 차순으로 정렬해야 하는데 정렬된 순서에 따라 자녀 노드들의 key 값의 범위가 결정되기 때문이다. 이런 방식으로 B-Tree를 사용하면 자녀 노드의 최대 개수를 필요에 따라 결정해서 쓸 수 있다.
B-Tree의 주요 네 가지 파라미터
위 내용을 봤듯이 B-Tree에서 최대 몇 개의 자녀 노드를 가질 것인지가 중요한 파라미터라고 할 수 있고, B-Tree에서 어떤 파라미터가 있는 살펴보자.
- 각 노드의 최대 자녀 노드 수(M): 최대 M개의 자녀를 가질 수 있는 B-Tree를 M차 B-Tree라 부른다.
- 각 노드의 최대 key 수(M - 1): 최대 자녀 노드 수를 결정하면 결정되는 파라미터 값이다.
- 각 노드의 최소 자녀 노드 수([M/2]): 3차 B-tree인 경우에는 3/2 = 1.5이므로 올림을 통해 3차 B-Tree에서 최소 자녀 노드 수는 2개 이다. root node와 leaf node는 제외한다.
- 각 노드의 최소 key 수([M/2] - 1): 위 최소 자녀 노드 수가 2개라면 최소 key 수는 1을 의미하고, root node는 제외한다.
B-Tree 노드의 key 수와 자녀 수의 관계
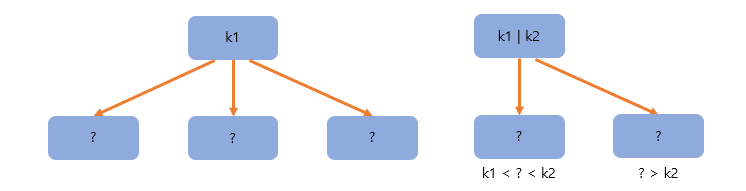
그러면 B-Tree에서는 위와 같은 구조를 가질 수 있을까? B-Tree는 internal 노드의 key 수가 x 개라면 자녀 노드의 수는 언제나 (x + 1)개이므로 현재 부모 노드의 수는 2개인데 자녀 노드의 수도 2개이기 때문에 규칙을 위반하므로 위와 같은 구조를 절대 가질 수 없다. 그리고 키가 하나인 경우에도 자식 노드가 2개이어야 하므로 3개인 경우에는 규칙을 위반한다고 할 수 있다. 따라서 키가 2개일 때에는 제일 처음 B-Tree 그림처럼 자녀 노드가 3개인 경우 또는 키가 1개일 때는 자녀 노드가 2개인 경우에 B-Tree 구조가 되는 것이다.
그리고 위 내용을 통해 노드가 최소 하나의 key는 가지기 떄문에 몇 차 B Tree 인지와 상관없이 internal 노드는 최소 두 개의 자녀를 가진다는 것을 알 수 있고, M차인지 정해지면 root 노드를 제외하고 internal 노드는 최소 [M/2]개의 자녀노드를 가질 수 있게 된다.
B Tree 데이터 삽입

데이터 삽입의 대표적인 특징은 항상 leaf 노드에서 발생하고, 노드가 넘치면 가운데 key를 기준으로 좌우 key들을 분할하고 가운데 key는 승진시킨다는 것이다. 위 그림처럼 40 데이터가 삽입되었다고 가정해보자. 그러면 루트 노트에서 7과 15를 비교했을 때 둘 보다 크기 때문에 가장 오른쪽으로 30과 70을 비교했을때는 가운로 이동하여 키가 50과 60이 있는 노드로 이동할 것이다.

그러면 위 그림처럼 키들을 정렬된 형태로 만들어야하기 때문에 40, 50, 60이 되고, 노드가 넘쳐버렸기 때문에 가운데 값 50을 기준으로 40과 60을 분리시키고, 50이라는 값은 승진시켜줘야 한다.

그러면 위와 같은 형태가 되는데 이러면 30, 50, 70 노드에서도 마찬가지로 가운데값 50을 기준으로 30과 70을 분리하고, 50을 승진시켜주면 아래 그림과 같은 형태가 된다.

역시 마찬가지로 50을 승진시킴으로써 7, 15, 50에서 키가 넘치게 되고, 이 키를 15를 기준으로 7과 50을 분리한 다음 15를 승진시키면 마지막으로 15 키를 가진 노드에서 왼팔과 오른팔로 각각 7과 50 노드를 가리키면 아래와 같은 형태로 된다.

위는 40 데이터가 들어왔을 때의 최종 형태인데 이를 통해 알 수 있는 것은 B Tree의 모든 leaf 노드들은 같은 레벨에 있다, 즉 Balanced Tree라는 것이다. 따라서 데이터 조회를 할 때 average/worst case가 모두 O(log N)로 일정한 성능을 낼 수 있다.
B Tree 데이터 삭제

데이터 삭제에서는 위에서 봤던 B Tree 네 가지 파라미터 중 각 노드의 최소 key 수가 [M/2] - 1개라는 특징을 통해 삭제 후 최소 key 수보다 적어졌다면 재조정할 필요가 있. 그리고 데이터 삭제도 데이터 삽입과 마찬가지로 항상 leaf 노드에서 발생한다.
위 B Tree에서 5 데이터를 삭제한다고 가정해보자. 그러면 초록색을 통해서 leaf 노드로 내려가고 5 데이터를 삭제할 것이다. 하지만 여기서 5를 삭제하고 나면 해당 노드에는 아무런 키도 존재하지 않게 된다. 그러면 3차 B Tree의 각 노드의 최소 key 수가 1개라는 조건을 위반하는 것이기 때문에 해당 노드를 아래 세 가지 방법의 재조정을 통해 해결해줘야 한다.
- key 수가 여유있는 형제의 지원을 받는다.
- 1번이 불가능하면 부모의 지원을 받고 형제와 합친다.
- 2번 후 부모에 문제가 있다면 거기서 다시 재조정한다.
1. key 수가 여유있는 형제의 지원을 받는다.

형제 노드의 key 수가 여유가 있기 때문에 받으려고 하는데 이 때 B Tree의 위처럼 정렬된 특징을 지키면서 지원을 해줘야할 필요가 있다. 따라서 부모로부터 3을 받고 왼쪽 노드의 2를 부모 노드로 올려주는 방식으로 형제의 지원을 받으면 아래와 같은 형태로 B Tree의 조건을 유지할 수 있게 된다.

이번에는 3 데이터를 삭제한다고 가정해보자. 이번에도 마찬가지로 형제의 지원을 받을 수 있는데 B Tree의 정렬된 특성을 유지하면서 지원을 해줘야 하기 때문에 8을 부모 노드로 7을 자식 노드에게 지원해줌으로써 위와 같은 형태로 B Tree 조건을 유지하면서 키를 삭제할 수 있다.
2. 형제의 지원이 불가능하면 부모의 지원을 받고 형제와 합친다.
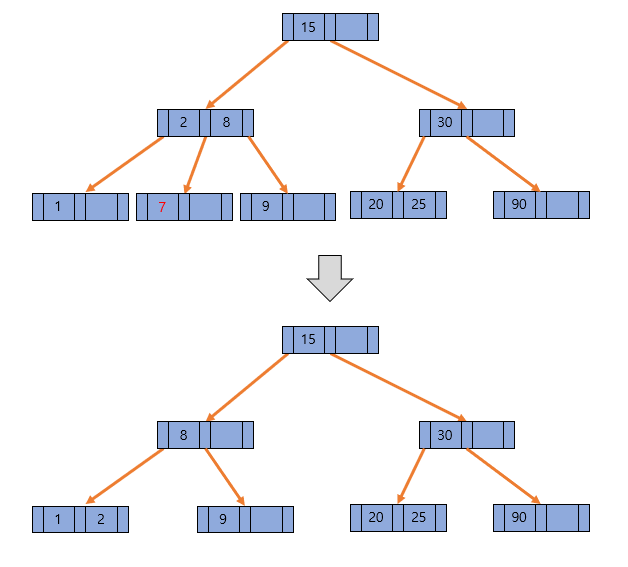
그 다음 7을 삭제한다고 가정해보자. 하지만 이 때는 이전과 다르게 형제의 지원을 받지 못한다. 따라서 부모의 지원을 받고 형제와 합칠 필요가 있다. 위 그림을 보면 2를 왼쪽 자식 노드로 이동하고, 7이 있던 노드와 합치려는데 7이 있던 노드는 합칠 키가 없으므로 그대로 삭제를 한다. 그 다음 부모 노드에서 8을 왼쪽으로 옮기면서 자신의 오른쪽 자식노드를 가리키는 포인터도 같이 이동시킨다. 그러면 3차 B Tree의 각 노드의 최소 key 수가 1개라는 조건을 유지하면서 데이터를 삭제했다.

이번에는 2를 삭제하고, 1을 삭제한다고 가정해보자. 2를 삭제해도 해당 노드에 key가 1개 남아있기 때문에 그대로 문제없이 삭제를 할 수 있다. 그리고 1을 삭제하게 되면 마찬가지로 부모의 지원을 받은 다음 형제와 합칠 필요가 있다. 따라서 위 그림과 같은 형태가 될 텐데 비어 있는 자식 노드는 삭제하며 되지만 부모 노드도 B Tree 조건을 위반하고 있는 문제가 발생했다.
3. 부모가 지원한 후 부모에 문제가 있다면 상황에 맞게 대응

부모 노드에서도 마찬가지로 형제 노드로부터 지원을 받으려고 하지만 지원을 받을 수 없는 경우에 2번 부모 노드의 지원을 받은 후 형제 노드와 합치면 된다. 그리고 30이 가리키고 있는 왼쪽 오른쪽 포인터 모두 같이 이동시키면 된다. 그리고 루트 노드가 비게 되는데 이 때는 루트 노드를 삭제하고 15, 30 키를 가진 노드를 루트 노드로 만들어 B Tree의 조건을 유지하면서 삭제할 수 있다.
internal 노드 데이터 삭제

위 데이터 삭제에서 leaf 노드에서 삭제하고 필요하면 재종한다고 얘기했었다. 그러면 internal 노드에서 데이터 삭제가 필요한 경우에는 어떻게 할 수 있을까? 만약 internal 노드에 있는 데이터를 삭제해야 한다면 leaf 노드에 있는 데이터와 위치를 바꾼 후 삭제하면 된다. 여기서 한 가지 이슈가 leaf 노드에 있는 데이터 중에 어떤 데이터와 위치를 바꿔줄 것인지가 중요한데 삭제할 데이터의 선임자(predecessor: 나보다 작은 데이터들 중 가장 큰 데이터)나 후임자(successor: 나보다 큰 데이터들 중 가장 작은 데이터)와 위치를 바꾸면 된다.
위 B Tree를 예제로 들면 15를 삭제하려고 할 때 선임자를 찾는다면 처음에는 왼쪽 자식 노드로 갔다가 계속 오른쪽 리프노드로 항하면 9 데이터가 선임자가 되어 15와 바꾼 후 위 데이터 삭제 과정으로 처리하면 된다.
DB 인덱스(index)로 B Tree 자료구조를 사용하는 이유
| tree | B tree(B+ tree, B* tree) | self-balancing BST | ||||
| case | AVL tree | Red-Black tree | ||||
| 조회 | O(log N) | O(log N) | O(log N) | |||
| 삽입 | ||||||
| 삭제 | ||||||
위 B tree 외에 self-balancing BST인 AVL tree와 Red-Black Tree를 보면 모두 조회, 삽입, 삭제 시 O(log N)이라는 것을 알 수 있다. 그러면 모두 시간 복잡도가 동일한데 DB index로 B Tree 계열이 사용되는걸까? 이에 대해서 이해하기 위해서는 컴퓨터 시스템에 대해 이해할 필요가 있다.
Computer System
- CPU: 프로그램 코드가 실제로 실행되는 곳
- Main Memory(RAM): 실행 중인 프로그램의 코드들과 코드 실행에 필요한 혹은 그 결과로 나온 데이터들이 상주하는 곳
- Secondary storage(SSD or HDD): 프로그램과 데이터가 영구적으로 저장되는 곳, 실행 중인 프로그램의 데이터 일부가 임시 저장되는 곳
데이터베이스도 당연히 Secondary storage에 저장이 되고, 디스크 특징에 대해서 살펴보자. 디스크는 컴퓨터 시스템 중에서도 가장 느리기 때문에 데이터베이스 서버에서는 항상 디스크 장치가 병목이 된다. 대신 데이터를 저장하는 용량이 가장 크며, block 단위로 데이터를 읽고 쓴다.
여기서 block이라고 하는 것은 file system이 데이터를 읽고 쓰는 논리적인 단위를 말한다. block의 크기는 2의 승수로 표현되면 대표적인 block size는 4KB, 8KB, 16KB 등이 있다. 따라서 block 단위로 데이터를 읽어오는 경우에는 불필요한 데이터까지 읽어올 가능성이 있다.
위 내용을 통해 DB에서 데이터를 조회할 때 디스크로부터 최대한 적게 접근하는 것 즉, I/O 작업이 적을 수록 성능 면에서 좋다는 것을 알 수 있고, block 단위로 데이터를 읽고 쓰기 때문에 연관된 데이터를 모아서 저장하면 더 효율적으로 읽고 쓸 수 있다.
AVL Tree INDEX(b) vs B Tree INDEX(b)

위 테이블에서 b 컬럼에 대해서 AVL Rree 기반의 인덱스와 B Tree 기반의 인덱스를 만들고 같은 제약 조건이 있다고 가정해보자.
- Tree의 각 노드는 서로 다른 block에 있다고 가정
- 초기에는 root 노드를 제외한 모든 노드는 디스크에 있다고 가정
- 초기에는 데이터 자체도 모두 디스크에 있다고 가정

먼저 AVL Tree 기반의 인덱스를 만들었을 때 AVL Tree는 위와 같은 형태로 만들어진다. 루트 노드가 6인 데이터부터 시작해서 b가 5인 데이터를 찾아보자. 5는 6보다 작기 때문에 왼쪽 포인터를 활용해서 디스크에 있는 노드 정보를 읽어와서 메인 메모리 상으로 올린 뒤에 5와 3을 비교한다. 그리고 5가 크기 때문에 오른쪽 자식 노드를 읽어오고, 4와 비교해서 5가 크기 때문에 오른쪽 자식 노드를 읽어오면서 5인것을 확인해서 인덱스에서의 조회는 끝나고, 해당 데이터 포인터가 가리키고 있는 레코드 주솟값을 통해 디스크로부터 데이터 파일의 실제 레코드를 읽어와야 한다. 그러면 메인 메모리에 원하는 데이터 정보가 올라와 데이터를 가공하여 요청에 대한 응답으로 돌려주면 된다. 이 과정에서 AVL Tree 기반의 인덱스는 디스크에 총 네 번에 걸쳐 접근한 것을 확인할 수 있다.
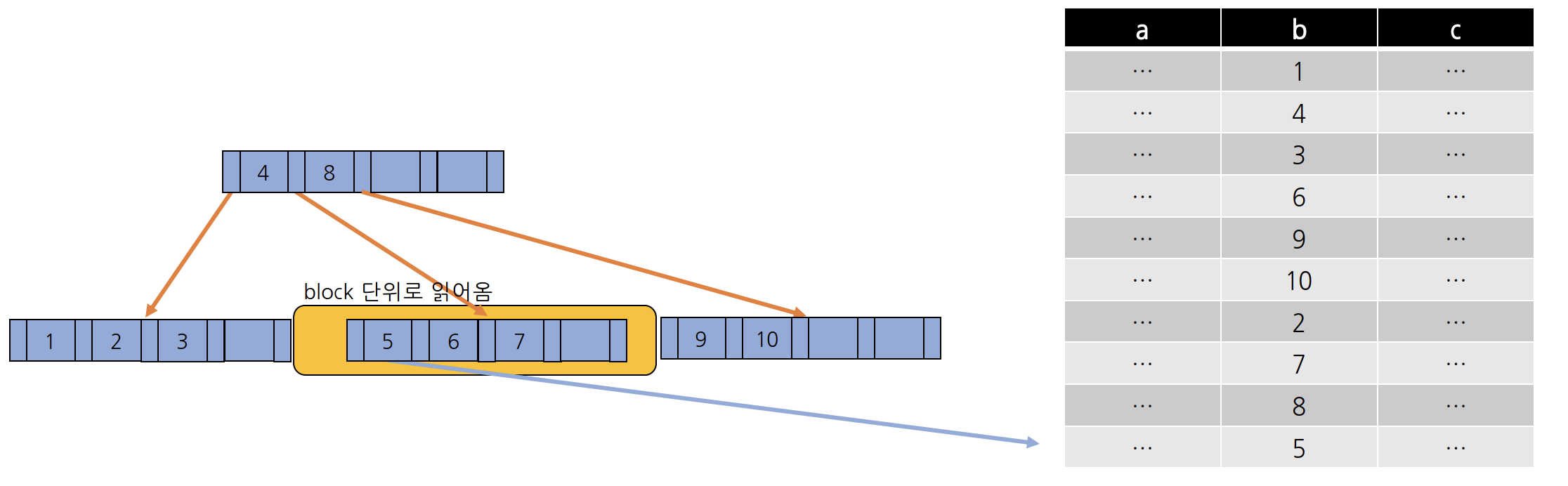
5차 B Tree 기반의 인덱스를 만들었을 때 5차 B Tree는 위와 같은 형태로 만들어진다. 똑같이 b가 5인 조건(where = 5)을 만족하는 데이터를 조회하면 루트 노드를 통해 4 보다는 크고 8보다는 작은 그 사이의 자식 노드로 이동하고, 해당 노드는 메모리 상에 올라와 있지 않기 때문에 디스크로부터 해당 데이터를 읽어 온다. 그리고 다시 5와 비교했을때, 5를 가지고 있기 때문에 인덱스에서의 조회는 끝나고, 마찬가지고 해당 데이터 포인터가 가리키고 있는 레코드 주솟값을 통해 디스크로부터 실제 데이터 파일의 정보를 읽어와 메모리 상으로 올린다. 이 과정에서는 디스크에 접근하는 과정이 두 번밖에 되지 않았다.
따라서 성능적인 측면에서 디스크를 덜 접근하는 B-Tree 자료구조를 사용한 인덱스가 훨씬 더 빠르다는 것을 알 수 있다. 그 이유는 두 자료구조의 자녀 노드 수를 비교했을 때, B Tree의 경우에는 3 ~ 5개까지의 자식 노드를 가질 수 있고, AVL Tree는 1 ~ 2개의 자식 노드를 가질 수 밖에 없다. 따라서 AVL Tree 기반의 인덱스는 데이터를 찾기 위해서 탐색하는 범위가 왼쪽 오른쪽 즉, 2 분의 1씩 탐색 범위를 줄여나가지만 B Tree는 최소 3 분의 1에서 5분의 1까지 탐색 범위를 줄여나갈 수 있다. 즉, B Tree가 AVL Tree 보다 데이터를 찾을 때 탐색 범위를 더 빠르게 좁힐 수 있다는 것을 알 수 있다.
그리고 노드가 가질 수 있는 데이터 수에도 차이가 있다. AVL Tree의 경우에는 각 노드가 하나의 데이터 밖에 가질 수밖에 없지만 B Tree 같은 경우에는 최소 2개에서 최대 4개까지 데이터를 가질 수 있다. 그리고 위에서 데이터를 읽어올 때는 block 단위로 읽어온다고 했을 때, AVL Tree는 해당 노드를 포함한 전체 block을 읽어오게 되는데 해당 노드 주위에 있는 데이터는 사실상 필요가 없는 데이터이다. 하지만 B Tree의 경우에는 한 노드에서 더 많은 데이터를 가질 수 있기 때문에 하나의 노드를 디스크로부터 block 단위로 읽어온다고 한다면 해당 노드를 포함하고 있는 block에는 AVL Tree보다 실제로 사용될 데이터들이 있다고 할 수 있다. 즉, block 단위에 대한 저장 공간 활용도가 더 좋다고 할 수 있다.
101차 B Tree
- 최대 자녀 수: 101
- 최대 key 수: 100
- 최소 자녀 수: 51
- 최소 key 수: 50
101차 B Tree를 통해서 B Tree가 얼마나 강력한지에 대해서 알아보자. 101차 B Tree의 경우에는 위와 같은 네 개의 파라미터를 가질 수 있다. 그리고 Best Case와 Worst Case를 나눠서 101차 B Tree가 얼마나 많은 데이터를 관리할 수 있을지 아래 표를 보면 확인할 수 있다.
| 101차 B Tree |
Best Case | Worst Case | ||
| 노드 수 | 데이터 수 | 노드 수 | 데이터 수 | |
| level 0 | 1 | 100 | 1 | 1 |
| level 1 | 101 | 101 * 100 | 2 | 2 * 50 |
| level 2 | 101^2 | 101^2 * 100 | 2 * 51 | 2 * 51 * 50 |
| level 3 | 101^3 | 101^3 * 100 | 2 * 51^2 | 2 * 51^2 * 50 |
Best Case인 경우에는 level 0인 경우에는 100개의 데이터 수를 가지고 101개의 자녀 수를 가진다. 그러면 level 1에서는 101개의 노드가 100개의 데이터를 다루고 레벨이 올라갈 때마다 101배씩 커진다고 할 수 있다. 이 때, level 3까지의 B Tree에서 관리할 수 있는 데이터 수는 총 104,060,400로, Level 3인데도 불구하고 대략 1억 개의 데이터를 관리할 수 있다.
Worst Case인 경우에는 Best Case와 다르게 데이터를 최소한으로 다루기 때문에 Level 0에서는 1개의 데이터만 다루고 2개의 자식 노드를 가지게 된다. Level 1에서는 노드 수가 당연히 2개, 이 때부터는 B Tree의 파라미터 조건을 지켜야하기 때문에 최소 가져야 하는 데이터 수는 50이므로 Level 1에서 데이터 수는 2 * 50이다. 이처럼 Level 3까지의 총 관리할 수 있는 데이터 수를 계산해보면 265,301개가 된다.
위 Case를 통해 101차 B Tree가 265301 < 전체 데이터 수 < 104,060,400개를 다룰 수 있으며, 루트 노드에서 가장 멀리 있는 데이터도 세 번의 이동만으로 접근할 수 있다는 장점이 있다.
인덱스를 사용할 때 주의사항
인덱스는 위에서 봤듯이 인덱스로 지정한 컬럼을 정렬한다. 모든 데이터를 검색해서 원하는 결과를 가져오려면 시간이 오래 걸리기 때문에 사전에 만든 인덱스를 사용하면 더 적은 I/O 작업을 통해 작업을 처리할 수 있다.
하지만 DBMS에서 인덱스는 항상 정렬해야 하므로 데이터의 저장(INSERT, UPDATE, DELETE) 성능을 희생하고 데이터의 읽기 속도를 높인다. 또한, InnoDB 테이블의 세컨더리 인덱스의 리프 노드는 실제 데이터 레코드를 찾아가기 위한 주솟값이 아닌 클러스터 인덱스인 PK 인덱스를 한 번 더 검색한 후, 프라이머리 키 인덱스의 리프 페이지에 저장되어 있는 레코드를 읽는다.
Clustered Index(PK를 AUTO_INCREMENT로 사용하는 것을 권장하는 이유)
위에서 InnoDB 테이블의 세컨더리 인덱스의 경우에는 리프 페이지에 실제 데이터 레코드 주솟값이 아닌 PK 값이 있어 PK 인덱스(클러스터 인덱스)를 한 번 더 검색한 후(프라이머리 키를 저장하고 있는 B-Tree를 다시 한 번 검색한 후) 프라이머리 키 인덱스의 리프 페이지에 저장되어 있는 레코드를 읽는다고 했다.
이렇게 PK로 정렬된 인덱스를 클러스터 인덱스라고 한다. 클러스터 인덱스의 경우, 테이블 당 단 하나의 Clustered Index만 존재할 수 있고, 인덱스 키 값에 따라 실제 데이터 레코드가 물리적으로 정렬되어 디스크에 정렬되어 저장된다. 클러스터 인덱스를 따로 지정하지 않으면, 기본키(PK)가 클러스터 인덱스가 된다. 따라서 데이터 입력, 수정, 삭제 시 항상 정렬 상태를 유지하고, 이를 통해 해당 레코드를 순차적으로 읽는 것이 가능하여 디스크 I/O를 최적화하고 데이터를 효율적으로 검색할 수 있다는 이점을 제공한다.
만약 클러스터 인덱스를 AUTO_INCREMENT가 아닌 주민번호, 이메일로 하는 경우에는 어떻게 될까? AUTO_INCREMENT와 같이 증가하는 숫자로 클러스터 인덱스로 사용하면 새로운 레코드가 항상 마지막에 추가되므로 데이터가 일정하게 분산된다. 하지만 주민번호나 이메일과 같은 식별자를 사용하면 값이 불규칙하게 입력되기 때문에 삽입, 삭제와 같은 작업을 수행하는 경우에 정렬을 유지하기 위해 리프 노드를 재배치하는 작업이 발생할 수 있어 자주 발생하거나 레코드가 많으면 많을수록 성능에 영향을 줄 수 있다.
AUTO_INCREMENT와 시간 기반 UUID 비교
위 내용을 통해 PK는 항상 정렬된 값이 드러와야 하기 때문에 UUID는 성능에 좋지 못하다는 것을 알았다. 그러면 AUTO_INCREMENT가 아닌 시간 기반 UUID를 사용할 수 있지 않을까?
다. 즉, 세컨더리 인덱스들은 PK(클러스터링 키) 값을 포함한다고 할 수 있다. 그래서 프라이머리 키의 크기가 커지면 세컨더리 인덱스도 자동으로 크기가 커진다. 일반적으로 테이블에 세컨더리 인덱스가 4 ~ 5개 정도 생성된다고 고려하면 세컨더리 인덱스 크기는 급격히 증가한다.
| PK 크기 | 레코드당 증가하는 인덱스 크기 | 100만 건 레코드 저장 시 증가하는 인덱스 크기 | |||
| 4 바이트 | 4 바이트 * 5 = 20 바이트 | 20바이트 * 1,000,000 = 19MB | |||
| 16 바이트 | 16 바이트 * 5 = 80 바이트 | 80바이트 * 1,000,000 = 76MB | |||
PK를 AUTO_INCREMENT로 하여 타입을 Integer로 지정한 경우에는 크기가 4바이트고, 시간 기반 UUID는 16바이트가 된다고 한다. 5개의 세컨더리 인덱스를 가지는 테이블을 비교하면 레코드 한 건일 때는 20바이트이지만 100만 건이 되면 인덱스의 크기는 거의 57MB(76MB - 19MB)가 된다. 1,000만 건이면 590MB가 차이나고, 테이블이 하나가 아니기 때문에 테이블 개수에 따라 또 그 차이는 더 늘어날 것으로 예상된다.
따라서 WHERE 조건절에 사용되는 컬럼이라고 해서 전부 인덱스로 생성하면 데이터 저장 성능이 떨어지고 인덱스의 크기가 비대해져 오히려 역효과만 불러올 수 있기 때문에 신중하게 선택해야 한다.
커버링 인덱스

커버링 인덱스는 데이터를 효율적으로 탐색하는 방법을 말한다. 인덱스를 사용해 조회하게 되면 실제 데이터까지 접근할 필요가 없어 조회 성능을 향상시킬 수 있다. 여기서 쿼리를 충족시킨다는 것은 SELECT, WHERE, GROUP BY, LIMIT, GROUP BY 등에서 사용되는 모든 컬럼이 인덱스 컬럼 안에 다 포함되는 경우를 말한다.
위 쿼리의 실행 계획을 보면 Extra 컬럼이 Using index 메시지를 출력한 것을 확인할 수 있다. 이 쿼리는 인덱스에 포함된 컬럼 id만으로 데이터 파일까지 갈 필요없이 인덱스로 처리가능하기 때문에 커버링 인덱스가 적용된 것이다.
만약 아래처럼 모든 컬럼을 조회해야 한다면 커버링 인덱스를 사용하지 못하고, 데이터 파일로부터 해당 레코드 정보를 읽어와야 한다.

풀 테이플 스캔을 선택하는 이유
그러면 검색을 빨리 수행하기 위해 인덱스를 사용한다는 것을 아는데 왜 풀 테이블 스캔을 선택하는 것일까? 사용자 테이블로부터 gender 컬럼을 조회했을 때 gender의 비율이 50 대 50이라고 가정해보자. 만약 gender에 인덱스를 걸어놨으면 어떤 스캔을 할까? 만약 gender 인덱스로 조회했으면 랜덤 I/O가 발생할 것이고 풀 테이블 스캔을 처리했다면 순차 I/O가 발생한다. 여기서 순차 I/O에서는 데이터를 연속된 블록을 묶어서 한 번에 읽어올 수 있기 때문에 블록 단위로 큰 데이터를 읽어오는 경우 효율적이고, 랜덤 I/O의 경우에는 특정 페이지 또는 블록 단위로 데이터를 읽어오기 때문에 순차 I/O보다는 비효율적이다.
따라서, 데이터를 송수신할 수 있는 대역폭은 무제한이 아니기 때문에 최대로 가져올 수 있는 사이즈가 있다. 이 때, 4개의 블록을 한 번에 읽어 2개의 블록을 버리는 것이 2개의 블록을 한 번씩 총 두 번 읽는 것보다 효율적이라는 것이다. 즉, 순차 I/O를 통해 디스크로부터 연속된 블록 단위로 한 번에 읽어와 나머지 50%를 버려 응답하는 것이 랜덤 I/O를 통해 더 많은 I/O 작업을 하는 것보다 더 효율적이기 때문에 인덱스 스캔 보다는 풀 테이블 스캔을 사용하는 것이다.
출처
(1부) B tree의 개념과 특징, 데이터 삽입이 어떻게 동작하는지를 설명합니다! (DB 인덱스와 관련있는 자료 구조)
(2부) B tree 데이터 삭제 동작 방식을 설명합니다 (DB 인덱스와 관련있는 자료 구조)
(3부) B tree가 왜 DB 인덱스(index)로 사용되는지를 설명합니다
댓글