통계 이야기
빅데이터 분석 ; 연관성 분석(2) ; kaggle 데이터에 적용
728x90
반응형
kggle에 있는 공개 데이터에 적용시켜보기
data <- read.csv("sales.csv")kaggle에 있는 슈퍼마켓 판매 데이터를 사용하였다.
8523개의 데이터와 12개의 변수들로 이루어져 있다.
str(data)데이터의 구조 살펴봄

attach(data)
table(data$Outlet\_Type)
table(data$item\_Type)몇 개나 이항자료로 변환시켜야하는지 table 함수로 빈도 수를 알아봄.
salesdata <- transform(data,
'dairy' = ifelse(Item_Type == "Dairy", 1, 0),
'soft drinks' = ifelse(Item_Type == "Soft Drinks", 1, 0),
'meat' = ifelse(Item_Type == "Meat", 1, 0),
'fruits and vegetales' = ifelse(Item_Type == "Fruits and Vegetables", 1, 0),
"household" = ifelse(Item_Type == "Household", 1, 0),
'baking goods' = ifelse(Item_Type == "Baking Goods", 1, 0),
'snack foods' = ifelse(Item_Type == "Snack Foods", 1, 0),
'frozen foods' = ifelse(Item_Type == "Frozen Foods", 1, 0),
'canned' = ifelse(Item_Type == "Canned", 1, 0),
'heaelth and hygiene' = ifelse(Item_Type == "Health and Hygiene", 1, 0),
'hard drinks' = ifelse(Item_Type == "Hard Drinks", 1, 0),
'starch foods' = ifelse(Item_Type == "Starchy Foods", 1, 0),
'breads' = ifelse(Item_Type == "Breads", 1, 0),
'breakfast' = ifelse(Item_Type == "Breakfast", 1, 0),
'seafood' = ifelse(Item_Type == "Seafood", 1, 0),
'grocery' = ifelse(Outlet_Type == 'Grocery Store', 1, 0),
'supermarket1' = ifelse(Outlet_Type == 'Supermarket Type1', 1, 0),
'supermarket2' = ifelse(Outlet_Type == 'Supermarket Type2', 1, 0),
'supermarket3' = ifelse(Outlet_Type == 'Supermarket Type3', 1, 0))범주형 자료를 이항자료로 변환.
salesdata <- salesdata[c(13:30)]
trans <- as.matrix(salesdata, "Transaction")
변환된 자료만 가져와서 matrix 형태로 만듬
library(arules)
rules1 <- apriori(trans, parameter = list(supp = 0.4, conf = 0.6, target = "rules"))
lhs rhs support confidence coverage lift count
[1] {} => {supermarket1} 0.6543471 0.6543471 1 1 5577
거의 모든 데이터들이 supermarket1과 큰 연관성을 가지는 것으로 해석할 수 있다.
rule <- apriori(trans, parameter=list(minlen=2))
rule <- apriori(trans, control=list(verbos=F), parameter=list(support=50/9835, confidence=0.6 ,minlen=2))
rule <- sort(rule, by='lift')
inspect(rule)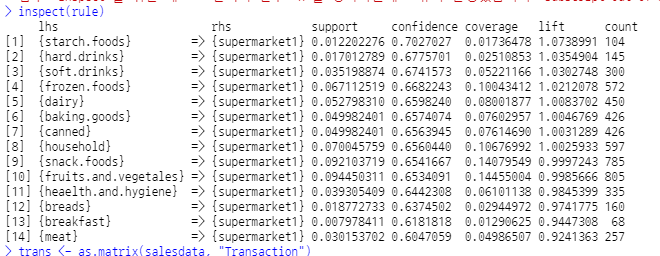
lift가 가장 큰 순서대로 순서를 세웠더니, 탄수화물이 가장 supermarket1과 연관성이 높은 것으로 나옴.
rule <- apriori(trans, parameter=list(support=0.0015, minlen=2),
appearance=list(none="supermarket2"))
inspect(rule)
set of 0 rules
rule_s <- apriori(trans, parameter=list(support=50/9835,confidence=0.6, minlen=2),
appearance=list(rhs="supermarket2",default='lhs'))
rule_s <- sort(rule_s, by='lift')
inspect(rule_s)
set of 0 rules -> supermarket2와 연관성은 높지 않다.
rule_s <- apriori(trans, parameter=list(support=50/9835,confidence=0.6, minlen=2),
appearance=list(rhs="supermarket1",default='lhs'))
rule_s <- sort(rule_s, by='lift')
inspect(rule_s)
plot(rule_s)
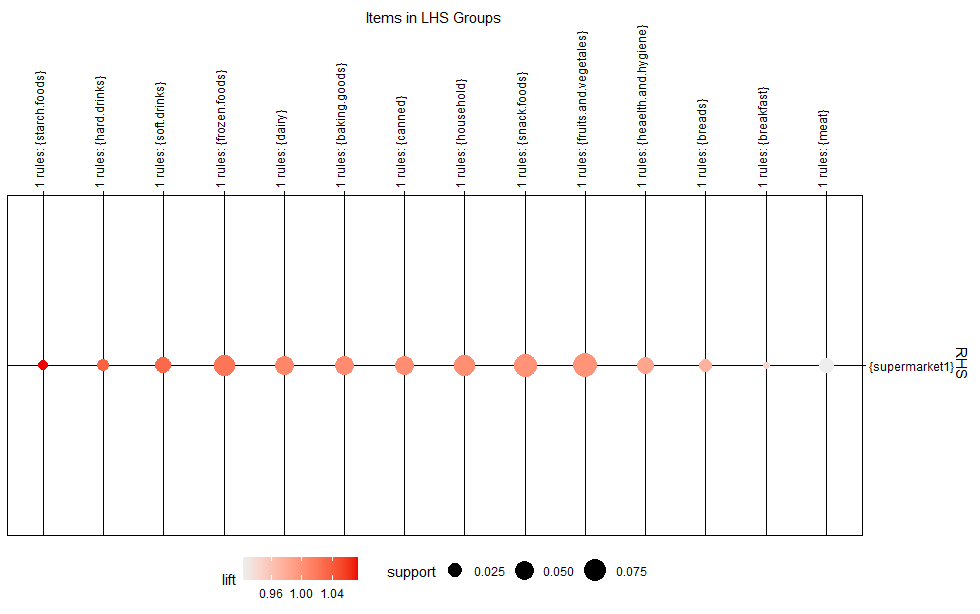
plot(rule_s,method="grouped")
plot(rule_s,method="graph")
plot(rule_s,method="paracoord")



728x90
반응형
'통계 이야기' 카테고리의 다른 글
| 빅데이터 분석 ; LDA ; logistic regression ; dicision tree ; 동시 비교 (0) | 2021.07.22 |
|---|---|
| 빅데이터 분석 ; logistic regression ; 로짓분석 ; 분류분석 ; classification analysis (0) | 2021.07.21 |
| 빅데이터 분석 ; LDA(선형판별분석) QDA(2차판별분석) (0) | 2021.07.20 |
| 빅데이터 분석 ; 연관성 분석(1) ; kaggle 데이터에 적용 (0) | 2021.07.18 |
| 빅데이터 분석하기 ; 데이터 탐색하기 (0) | 2021.07.16 |
댓글